
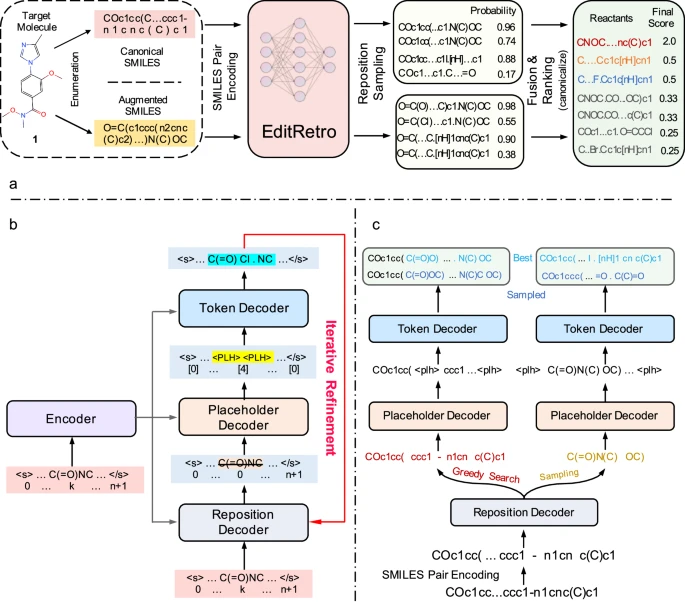
逆向合成是藥物發現和有機合成中的一項關鍵任務,人工智能(AI)越來越多地被用來加快這一過程。然而,現有的方法采用逐個令牌的解碼方法將目標分子串轉換為相應的前體,表現出不甚理想的性能和有限的多樣性。由于化學反應通常會引起局部分子變化,反應物和產物通常會明顯重疊。鑒于此,來自浙江大學的Huajun Chen,Tingjun Hou和Qiang Zhang等人提出將單步逆向合成預測重新定義為分子串編輯任務,迭代地細化目標分子串以生成前體化合物。
文章要點:
1) 該研究開發的這種方法涉及一種基于片段的生成編輯模型,該模型使用顯式的序列編輯操作,并且,該研究設計了一個具有重新定位采樣和序列增強的推理模塊,以提高預測精度和多樣性;
2) 此外,研究還通過大量實驗證明,這一模型生成了高質量和多樣化的結果,在標準基準數據集USPTO-50 K上實現了60.8%的top-1準確率,取得了卓越的性能。
參考資料:
Han, Y., Xu, X., Hsieh, CY. et al. Retrosynthesis prediction with an iterative string editing model. Nat Commun 15, 6404 (2024).
10.1038/s41467-024-50617-1
https://doi.org/10.1038/s41467-024-50617-1

















